
Foliage released
Foliage is a static web site generator pretty much like Octopress/Jekyll. Instead of being a tool you invoke from the commandline foliage is meant to be a library to create a customized web site with a script. The script can then be used to invoke foliage headless on a commandline. The basic idea of foliage is to reify all structures of the web site from filesystem hierarchy down to the HTML DOM. Every structure should accessible, modifiable to enable the creation of very flexible setups.
The name foliage most probably is caused by the german language. In german the word for a sheet of paper in a book and the leaf of tree can be described with the same word: Blatt. The same goes for having a collection of sheets of paper or a bunch of leafs, you can call both: Blätterwerk. In autumn when trees change color you get a tree with branches and beautiful colored leafs. And this is the same for me as a nice web site branches and colorful leaf pages. Hence I felt foliage might be something appropriate.
Disclaimer: Foliage is pretty basic right now. Basic things mentioned in this article work but I doubt you can do much without bumping in a problem of some sort. I release it in that state because people were asking me to do so. If you are on the brave side trying just send me a message or open a ticket if you encounter problems. This library is pretty much work in progress. I just started to write tests which means I'm just out of the orientation phase. You have been warned!
TL;DR
The repository of foliage can be found here. From within a pharo playground you can load it by executing the following:
Metacello new
repository: 'github://noha/foliage/src';
basline: #Foliage;
loadTo install the same theme that I use on my web site you can make this setup by invoking:
FOSkeletonTheme install that downloads the Skeleton CSS boilerplate and creates a basic page template that you can use.
The default paths are:
- raw for the source files
- template for templates
- docs for the produced web site that can be copied somewhere
If you use the default paths the website building is done with executing:
FOWebSite new
import;
publish.You should find the ready to use web site in the docs folder.
The long story
Some time ago I had the idea to (yet again) start a blog but also wanted to get back into dealing with a document model like pillar and the prodcution of HTML pages which is quite some time since I did the last time.
If you have read any of the blog articles available on this site the only content was to describe my way from nothing to a little tool I can now use to produce this web site. It has also a lot of the structure management functionality I want it to have.
An important goal of foliage is that content can be created very easy and then transformed into the form that is needed for publishing a web site. For creating page content I decided to use markdown because it is easy to write and the markup adds all needed structure while being lightweight when reading the raw text. This page content is put together with media files etc. into a directory structure that resembles the hierarchical layout we want to have on the web site.
a basic workflow
When writing a new blog article we can open a pharo playground and do (the raw folder is the default source path)
'raw' asFileReference inspectand we see the following:
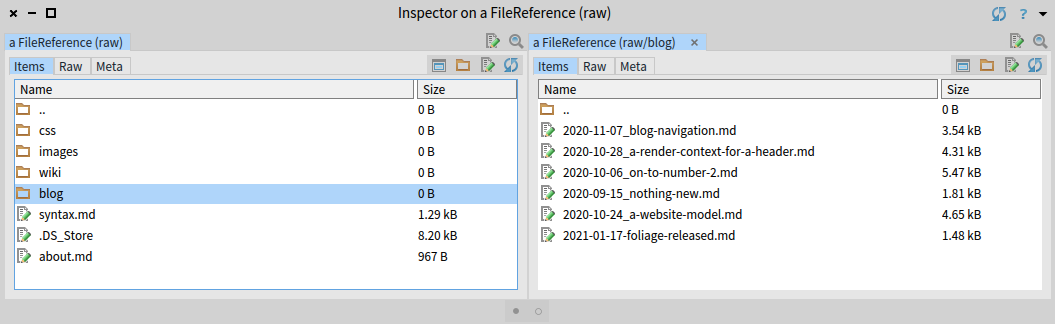
As usual in pharo everything is an object and this includes filesystem resources as well. The inspector shows us the whole web site structure and we are able to navigate through it. Selecting one of the posts enables us to edit its contents
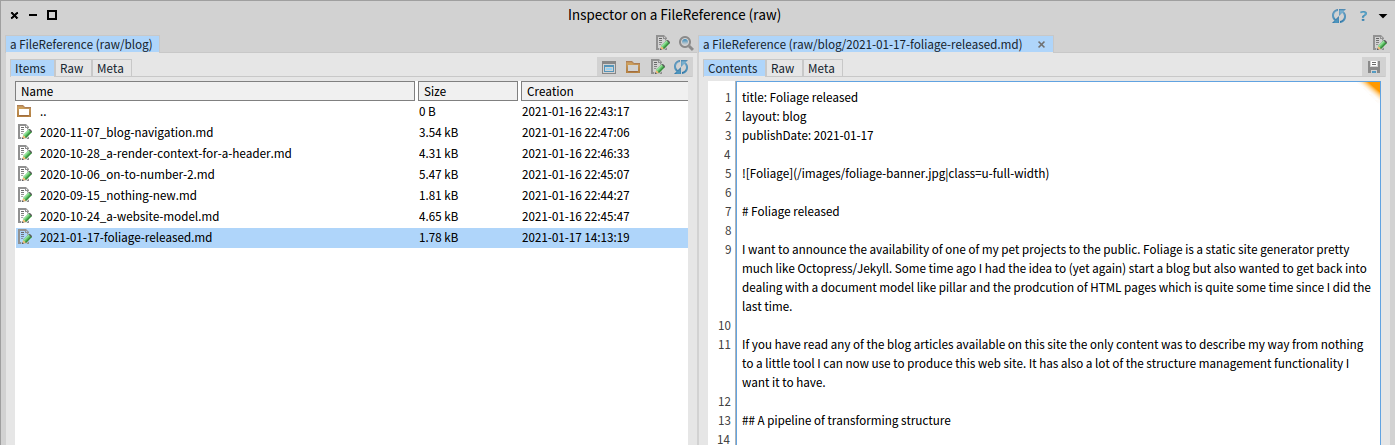
The right pane containing the text is editable and by using the short cut key cmd-s we just save the file back to the filesystem being ready for publishing.
creating the model
The basic workflow deals with entities that reside on disk. When writing an article we are not concerned with the web site generator at all. We focus on writing text. When it comes to publishing the site we need to manage and transform these disk based entities. We read the source entities in a model which parallels the structure from disk in memory.
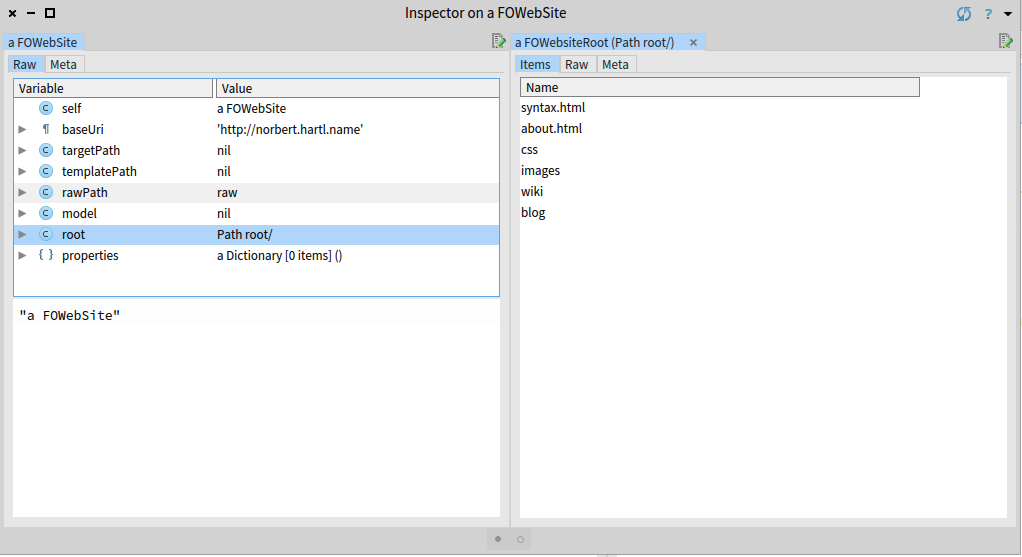
site := FOWebSite new
baseUri: 'http://norbert.hartl.name';
import;
inspect.This creates our website object and imports all the disk based entities in a model that we can manage and transform.
Using the document model
Generating pages from the source path in to the web site 1:1 is something useful. But there are many use cases that operate one the this content to generate new one. As showed in a previous post the blog overview page is one of them. We extend our script to add a web site section containing blog posts.
site := FOWebSite new
baseUri: 'http://norbert.hartl.name';
import.
site addBlogAt: site root / #blog.
site atPath: '/index.html' add: site blog overviewPage. The Blog object reads in all pages in the folder /blog and generates abstracts from them using a visitor that operates on the pillar document model of each page. The generated abstracts are then combined in a newly created page which we place in our model as the index.html of the blog folder.
Using the HTML DOM model
The pillar document model is the foundation of content in foliage. We can easily operate on it to extract and create data. But pillar does not reflect most of HTML so it is almost obvious that sometimes we develop the need to add HTML specific things which we cannot using pure pillar.
One exampe is the creation of an RSS feed for the site. We extend our script further
site := FOWebSite new
baseUri: 'http://norbert.hartl.name';
import.
site addBlogAt: site root / #blog.
site atPath: '/index.html' add: site blog overviewPage.
feed := site atPath: '/blog/rss.xml' add: (site rssFeed).
feed addHeaders.The RSS feed generator is in its working very close to the way the blog overview page works. It collects the posts and creates an XML file for the feed which can be read by a crawler to index the site way better. But in order to make the feed XML be found by the crawler it is useful by advertizing it. One way to do this is to have a HTML header added to the main page in the form
<link type="application/rss+xml" title="blog" href="http://norbert.hartl.name/blog/rss.xml" rel="alternate">In order to achieve this we make the HTML DOM available as another structure we can operate on. If we look at the #addHeaders method
addHeaders
| indexPage htmlDocument head |
indexPage := self website root / 'index.html'.
htmlDocument := indexPage htmlDocument.
head := (htmlDocument / #html / #head) first.
head addChild: ((SoupTag named: #link)
attributeAt: #rel put: self rel;
attributeAt: #href put: self href printString;
attributeAt: #type put: self linkType;
attributeAt: #title put: self title;
beSelfClosing ;
yourself )Using the Soup library we can parse HTML back into a DOM, search and traverse on it and change its content. The anatomy of a foliage page supports this. The basic use case for each page is to read markdown into pillar and use mustache to produce a HTML string. But if the HTML DOM of a page is accessed the HTML string is parsed back into a DOM so we can modify it. If the HTML DOM is present in a page the HTML string for publishing is produced from the DOM instead reading the markdown again. This way we can separate the page publishing into phases reaching from markdown over HTML into string while being able to modify content at each stage.
A pipeline of transforming structure
So while the implementation of foliage is pretty basic right now the fundamentals of what I wanted to do are present. If we look at the pipeline that lead to the addition of a HTML header for RSS feed it explains pretty much the goal of foliage:
- reading files as model into memory
- extracting blog posts from the web site structure
- generating a new page and put it in the in-memory model
- request the HTML DOM from the generated page and manipulate the DOM
- publish this to the target on the filesystem
This is a precise and short explanation of what we can do with foliage.
Questions and critiques welcomed as always